Do you have any suggestions on how to improve it? Maybe identify legit bots and do not log those?This makes the log pretty useless as it is spoiled with 100s of entries caused by bing that can only manually be identified by grepping through the web.log.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Custom 404 Page by Siropu 1.2.0
No permission to download
- Thread starter Siropu
- Start date
Could be an idea. A low hanging fruit would be to add the user agent to the log, possibly abbreviated, and in the next step to give the opportunity to filter on or a number of them out.Do you have any suggestions on how to improve it? Maybe identify legit bots and do not log those?
Reason is that potentially one wants to see if indexing bots get a 404 as this might be important for SEO ranking and maybe some of those are fixable.
In the perfect world one would have kind of clusters like bot/no known bot and within the bots cluster a classification into groups like wanted, unwanted/ignorable or eventually something like "Search engine indexing bot" or alike. If one could create or name such clusters indivually and add useragents to them manually this would be even better.
Could be complicated but on the other hand maybe be an interesting idea to somehow interact with "Known Bots" by @Sim
I think the most important thing is to know on the spot what source a request that results in a 404 has to be able to identify if and how one wants to deal with that 404. Everything on top of that is a comfort function that makes life easier and the tool more useful.
Could be complicated but on the other hand maybe be an interesting idea to somehow interact with "Known Bots" by @Sim
The good news is that my KnownBots addon simply extends the core functionality which already flags user sessions when it detects they are a bot - so if you want to indicate that somehow, the information is already there in the user session.
This URL appears as 404 in the records, but this URL is not listed on Google? How does this happen? Does this plugin also count bots? I don't understand?
Attachments
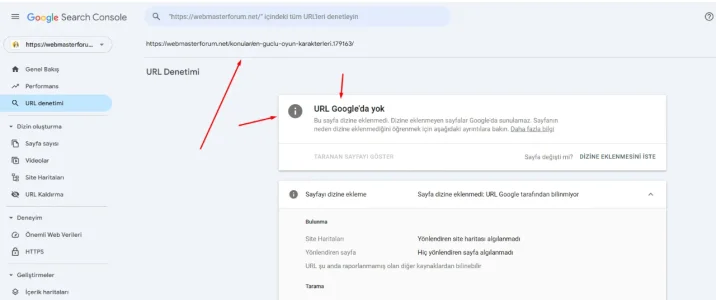
It counts 404 - page not found answers by XF. So it clearly counts in bots as well. You can easily crosscheck with your webserver log and will pretty safely find the call there (including the IP and useragent it came from).This URL appears as 404 in the records, but this URL is not listed on Google? How does this happen? Does this plugin also count bots? I don't understand?
Is there any reason why this table would by MyISAM?

I've also had to repair this table on a few of my customers servers as it was marked as crashed.
I've also had to repair this table on a few of my customers servers as it was marked as crashed.
Code:
MariaDB [XXXXXX]> SHOW TABLE STATUS LIKE 'xf_siropu_custom_404_page_not_found'\G
*************************** 1. row ***************************
Name: xf_siropu_custom_404_page_not_found
Engine: MyISAM
Version: 10
Row_format: Dynamic
Rows: 362210
Avg_row_length: 230
Data_length: 83663396
Max_data_length: 281474976710655
Index_length: 65752064
Data_free: 0
Auto_increment: 362211
Create_time: 2023-12-08 16:42:05
Update_time: 2025-06-10 15:58:19
Check_time: 2025-06-09 10:26:52
Collation: utf8mb4_general_ci
Checksum: NULL
Create_options:
Comment:
Max_index_length: 288230376151710720
Temporary: N
1 row in set (0.003 sec)You can convert it to innodb.Is there any reason why this table would by MyISAM?
So does this only work with links? I am cloud hosted and have some issues with people having booked mark the old site and are getting 404 (white pages) when they visit the site. I tried installing this but it didn’t seem to work.
It works with 404 pages generated in XF.I am cloud hosted and have some issues with people having booked mark the old site and are getting 404 (white pages) when they visit the site.
You need an older version: https://xenforo.com/community/resources/custom-404-page-by-siropu.7188/historyAlthough it is stated that the extension works with 2.2, when I tried to install it, a message appeared stating that it could not be installed because the version should be 2.3.
We can currently filter on URL and we can filter on 'without redirect', but we cannot combine these filters. Please add functionality to combine these.
It would also be very useful to search for part of the URL. For example, I have a large number of 404 entries because the code {valueRaw} does not work in XF2. I changed the code and resolved these entries. Now I need to find a way to find and delete them.
I would also like to be able to bulk delete entries. We added a redirect of /ams/comment/* to ams/comments/*
But 8k entries for /ams/comment/ stay visible in the list and pollute it. This makes it really hard to see what we still need to address. There are multiple such examples causing tens of thousands of entries to be listed that are already addressed.
It would also be very useful to search for part of the URL. For example, I have a large number of 404 entries because the code {valueRaw} does not work in XF2. I changed the code and resolved these entries. Now I need to find a way to find and delete them.
I would also like to be able to bulk delete entries. We added a redirect of /ams/comment/* to ams/comments/*
But 8k entries for /ams/comment/ stay visible in the list and pollute it. This makes it really hard to see what we still need to address. There are multiple such examples causing tens of thousands of entries to be listed that are already addressed.
Last edited:
Hi
How to disable log /admin.php?404-not-found/
and have only 404 page?
Thank You
How to disable log /admin.php?404-not-found/
and have only 404 page?
Thank You
Last edited:
No such option but can be added.How to disable log /admin.php?404-not-found/
and have only 404 page?
IS there a best practice to redirect to this 404 page from OUTSIDE the xf install?
I have a forum in a /directory/ and i would like the / root dir to also have a same-theme 404.
Thinking i can just do an htaccess in root to have ErrorDocument 404.shtml type indicator, but what IS that 404.shtml equivalent? In other words, how do i force a 404 landing page without creating a dead page on purpose?
I have a forum in a /directory/ and i would like the / root dir to also have a same-theme 404.
Thinking i can just do an htaccess in root to have ErrorDocument 404.shtml type indicator, but what IS that 404.shtml equivalent? In other words, how do i force a 404 landing page without creating a dead page on purpose?
IS there a best practice to redirect to this 404 page from OUTSIDE the xf install?
I have a forum in a /directory/ and i would like the / root dir to also have a same-theme 404.
Thinking i can just do an htaccess in root to have ErrorDocument 404.shtml type indicator, but what IS that 404.shtml equivalent? In other words, how do i force a 404 landing page without creating a dead page on purpose?
Try creating a file 404.php in the root directory of the domain
PHP:
<?php
$_SERVER['REQUEST_URI'] = '/__root404__';
$_SERVER['SCRIPT_NAME'] = '/directory/index.php';
$_SERVER['PHP_SELF'] = '/directory/index.php';
require __DIR__ . '/directory/index.php';And add this to .htaccess (main directory)
ErrorDocument 404 /404.php
Of course, the forum /directory/ must have its own original .htaccess with its own rules...
Please add search / filter for redirects.
The search function does not work when you click 'With redirect'.
If you click 'With redirect' first and then use search, then it will not search for links with redirect.
If you first use search and then click 'With redirect' then the page will just refresh and the search results gone.
This seems buggy.
The search function does not work when you click 'With redirect'.
If you click 'With redirect' first and then use search, then it will not search for links with redirect.
If you first use search and then click 'With redirect' then the page will just refresh and the search results gone.
This seems buggy.
Same here, also bing for some reason.second one:
msnbot-40-77-167-76.search.msn.com - - [08/Apr/2025:14:26:41 +0200] "GET /threads/Threadurl.1338/Picture-Name.jpg HTTP/1.1" 404 9505 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) Chrome/116.0.1938.76 Safari/537.36" 796 14614
There are hundreds of those. The requested picture does exist (it is embedded in the thread) but as full size pictures are only accessible to logged in users the bot won't get the ful resolution pic. It would however have a different URL than the bot requested anyway - no idea where he got his from.
Last edited:
How would you identify a deleted thread URL? If you can do that it is easy to achieve in .htaccess. If you can't you're probably out of luck.How can I redirect deleted threads from 404 to 410 status? Can you share the regex or any other method?
Similar threads
- Replies
- 4
- Views
- 811
- Replies
- 2
- Views
- 450
- Replies
- 11
- Views
- 886
- Replies
- 1
- Views
- 1K
- Replies
- 0
- Views
- 590