- Affected version
- 2.2.13
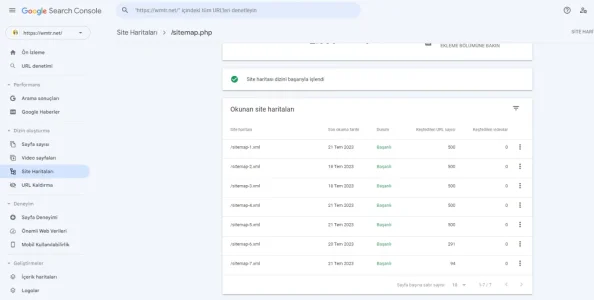
XenForo Sitemap File has 50,000 urls, which is not very popular and accepted in terms of google and seo. While this number is limited to 300-500 in all other infrastructures, it is a pity that there is no such option in xenforo. On the other hand, opening and accessing a sitemap file with 50,000 URLs is a serious problem for small and medium-sized servers. I hope there will be a nice improvement in the next update.


")