I will come with results and keep you updated, pinky promise. So far, I have a plan about XenForo SEO internal linking Web App Version 2 that runs locally (not that I made it myself; Claude Opus and Gemini Pro made it to help a noob, my goodness, such kindness; let's see how it goes! My current AI stack is Claude Code, Codex, and Google Antigravity.
I am just a noob who has no idea what I am doing. It's all about the vibes, I guess. I am a dog chasing cars. I just do things.

Also, Claude Opus suggested we use PageRank (a paper published in 1998 by Sergey Brin and Lawrence Page), which Claude also said we should use stuff that I have no idea how it works, although I did a little bit of prior research on Gemini Pro to explain like I am five, but I still can't understand why or how it will add up (it's vibes, I guess). Claude suggested, e.g., Django, Angular, PostgreSQL, Docker, Redis, multi-qa-MiniLM-L6-cos-v1 (GPT OSS 120b, later when I buy a super cool GPU and PC with tonnes of RAM, but RAM is expensive these days innit?), PyTorch, spaCy, and NVIDIA CUDA for sentence transformers, whatever that means.
This was my initial prompt to Claude Opus after asking Gemini Pro about XenForo SEO internal linking. It was written by Gemini Pro after going back and forth with it, and also because my grammar is so bad, English isn't my first language after all, at least I try, with the help of Grammarly.
Gemini Pro's prompt to tell Claude Opus what to do. Call it "prompt chaining," if you will, asking an LLM to ask another LLM to complete a task.
Gemini's revised prompt:
I am just a noob who has no idea what I am doing. It's all about the vibes, I guess. I am a dog chasing cars. I just do things.
Also, Claude Opus suggested we use PageRank (a paper published in 1998 by Sergey Brin and Lawrence Page), which Claude also said we should use stuff that I have no idea how it works, although I did a little bit of prior research on Gemini Pro to explain like I am five, but I still can't understand why or how it will add up (it's vibes, I guess). Claude suggested, e.g., Django, Angular, PostgreSQL, Docker, Redis, multi-qa-MiniLM-L6-cos-v1 (GPT OSS 120b, later when I buy a super cool GPU and PC with tonnes of RAM, but RAM is expensive these days innit?), PyTorch, spaCy, and NVIDIA CUDA for sentence transformers, whatever that means.
This was my initial prompt to Claude Opus after asking Gemini Pro about XenForo SEO internal linking. It was written by Gemini Pro after going back and forth with it, and also because my grammar is so bad, English isn't my first language after all, at least I try, with the help of Grammarly.
Gemini Pro's prompt to tell Claude Opus what to do. Call it "prompt chaining," if you will, asking an LLM to ask another LLM to complete a task.
Gemini's revised prompt:
Code:
I am incredibly excited to begin building this project using Django, Angular, and PostgreSQL. We will need to set up a new repository called XF Internal Linker V2 and establish a solid master plan. Because I am a beginner, I need step-by-step guidance utilizing purely GUI tools, so I never have to touch the command line. Please guide me with kindness while remaining brutally honest about maintaining excellent coding practices. I have already completed dozens of UI slices, designing the interface to mirror the layout and colors of Google Search Console, though features like websockets remain unfinished. I also uploaded a file to my server that must be synced with our new stack.
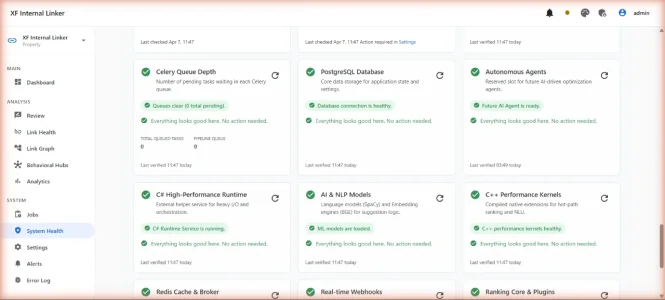
We must create an enterprise-grade, fast, and highly efficient architecture that runs smoothly on my current PC with 16 GB of RAM. The design must be forward-thinking and highly scalable right from the start, keeping in mind my plans to purchase a much more powerful computer to run heavy AI models like gpt-oss-120b. The application needs precise resource management, meaning it should completely shut down when not actively running. It must support two execution modes: a balanced mode that relies solely on the CPU and a high-performance mode that utilizes both the CPU and GPU. Portability is also crucial, so the app should be designed for easy migration via Docker to other local machines or web servers. Furthermore, the architecture should support modular plugins to ensure backward compatibility and be built to accommodate Elasticsearch in the future.
The primary purpose of this read-only application is to scan content and generate internal linking suggestions without directly modifying my XenForo or WordPress databases. The contextual linking strategy should scan only the first 600 words of a thread and suggest a maximum of three links per post. These suggestions should lean toward long-tail anchor text, utilizing an anchor policy engine that bans generic anchors, limits exact-match reuse, and prefers natural variants while clustering topics to avoid cannibalization. The app must seamlessly integrate with the XenForo REST API, WordPress REST API, and XenForo Media Gallery. It should heavily utilize XenForo webhooks to trigger instant ranking pipelines upon new thread creation, auto-verify applied links, and flag stale suggestions if a post is deleted. To ensure reviewers do not act on outdated content, the app must run live stale checks and duplicate checks before any approval.
The frontend must be as flexible as WordPress, allowing complete customization down to every specification through a theme panel. The Django admin side should be exceptionally user-friendly, offering organized content categories and intuitive configuration pages. For the actual review process, the app needs a Zen-like focus mode that displays one suggestion at a time with large keyboard-friendly controls. Reviewers should see a side-by-side live diff preview, pulling the latest raw post message from XenForo and showing the proposed final edit locally before they manually paste and save it elsewhere. We also need an item-level explorer that explains why no suggestion was made for specific content, along with excellent error reporting and live warnings for canonical URL issues or redirect failures. Redis should be implemented to ensure lightning-fast, real-time results, carefully caching only what is necessary and respecting strict age limits.
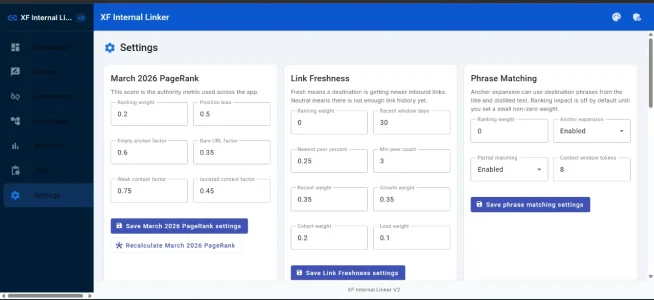
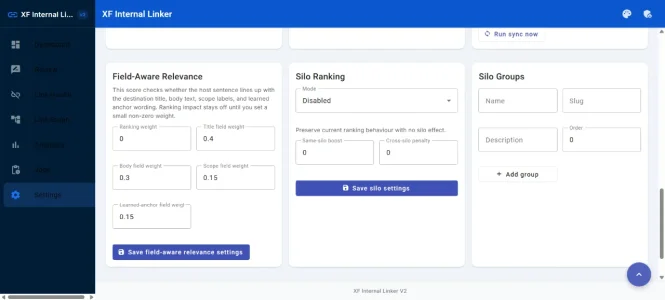
Comprehensive analytics and tracking are vital to evaluating the success of our internal linking strategy. The application should integrate seamlessly with the Google Search Console API and GA4 to pull actual search performance data without exceeding rate limits. We need visual tools like a unified PageRank graph spanning both the forum and the blog, a two-dimensional or three-dimensional link graph to identify orphan content and highly linked hubs, and a link density heatmap to prevent link fatigue. The dashboard should feature materialized views for underlinked content and review backlogs, alongside reviewer scorecards that track approval rates and rejection reasons. Furthermore, the app must provide actionable insights, such as an SEO gap analysis for missing keywords and before-and-after impact reports built with beautiful D3 visualizations to track ranking, views, and engagement changes following manual link applications.
Finally, we must maintain impeccable documentation and strict development workflows. A dedicated AI-context.md file must be utilized and continuously updated whenever tools like Codex, Antigravity, or Claude Code are involved. If it is safe to do so, commits and pushes to GitHub should happen automatically. The application should also provide regular prompts to check for errors, run updates, handle dependencies gracefully, and request new features, ensuring the entire ecosystem remains up-to-date, adaptive, and dynamic.